近期的AI折腾心得
前言
最近新装了一台PC,终于用上了相对不错的硬件(i7-14790F+5060ti 16G),比起我的老3060笔记本自然是一大飞跃。
于是,这么好的硬件不拿来跑AI也太可惜了 : )
已部署的应用
LLM和VLM系列
推理开源大语言模型和视觉语言模型。
主要使用LM studio(即llama.cpp)做GGUF格式模型的推理+API服务器。
此外还部署了text-generation-webui使用ExLlamaV3后端实现高速推理,目前仍处于实验阶段,但测试qwen3-coder-25b-a3b生成速度会比gguf格式的qwen3-30b-a3b快非常多(前者可达50-60 token/s,虽然说经过专家剪枝本身也更轻量,但相比后者的推理速度只有10 token/s而言仍然是非常快的)。
未来计划接入vllm提供更大的灵活性和更多模型选择。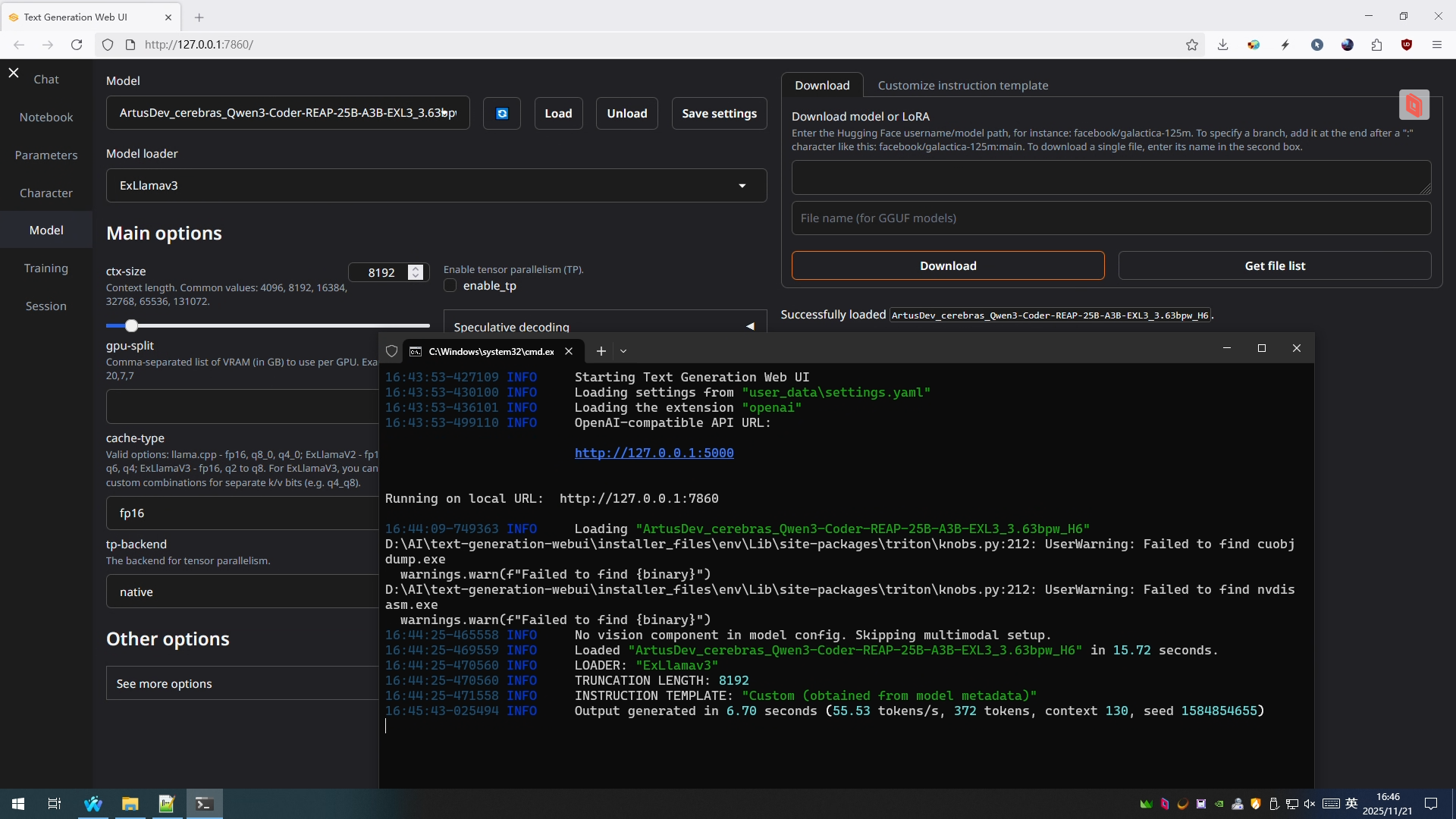
(图:使用ExL3后端进行高速推理)
前端应用:streamsim
从Websim里的同名项目fork过来并改造了一下,可以利用本地VLM实现模拟直播。虽然目前测了qwen3-vl-8b效果没有想象中的好,不过还是能用的。之后试试gemma-3-12b。
图像和视频生成
图像生成主要是扩散模型,如stable diffusion、flux等。
目前只是装了ComfyUI,但没有安装真正的生图模型。
视频生成目前有wan2.2可以做I2V,计划未来继续增加T2V模型。
但Comfy的环境配置实在是太头疼了,这个软件可能会暂时搁置一会。(没错就是那个songGeneration的custom_node,我一安装就会直接启动不了Comfy,直接把我整个环境干废了必须从头重装所有依赖;掉了三次坑之后我直接去社区找成品一键包😤)
(暂时没图,comfy以后有心情了再折腾,也算是侧面体现出python整个环境和依赖管理的混乱不堪吧)
音乐生成
包括几个流行的高质量音乐生成项目:diffrhythm、ACE-Step,以及腾讯的songGeneration。
都是以一键包的形式单独部署的,但都有WebUI提供。
不过本地模型的生成质量确实还是不够看,songGen的总体质量最高但仅限于华语乐坛风格(流行音乐和情歌最为优秀),电子音乐则完全无法驾驭。
未来计划就是当玩具了,真想使用的话还得是Suno。
等待更有实力的模型出现.png
(图:songGen webui)
3D模型生成
同样是腾讯的Hunyuan-3D-2。
从GitHub上找的一键包,最新有2.1但不支持T23D(文本到3D)。不过文本生成模型的原理是先生成图片再生成3D,所以之后计划接入更强大的文生图模型实现更高质量的工作流。
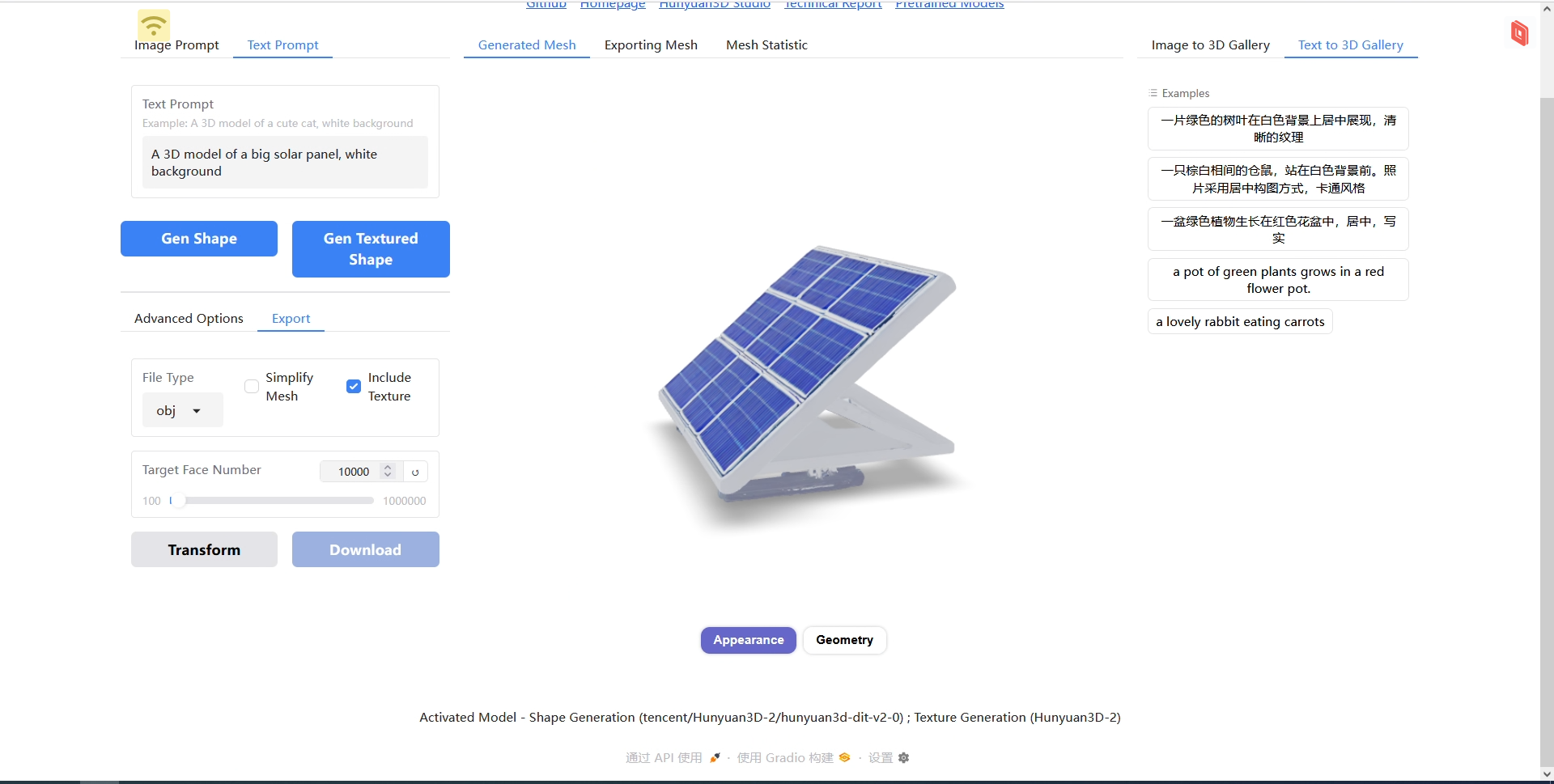
(图:文生3D结果)
音乐内容分离(STEMS)
使用MDX23做AI音乐人声分离。
项目仓库:github:MVSEP-MDX23
目前应该还是效果最好的开源模型之一,效果可以达到我的标准了。自己测试比demucs4更好,虽然demucs的速度快不少(在3060上就可以20s一首,5060ti加上前后处理不超过10s)。
50系显卡不能直接用releases提供的Windows包,因为torch版本不支持新显卡。我是clone仓库之后新建venv然后从头pip install -r requirements.txt装的,应该不会有啥问题,最多就是torch自己提前装上cu130的最新版。
顺便写了个GUI方便自己用: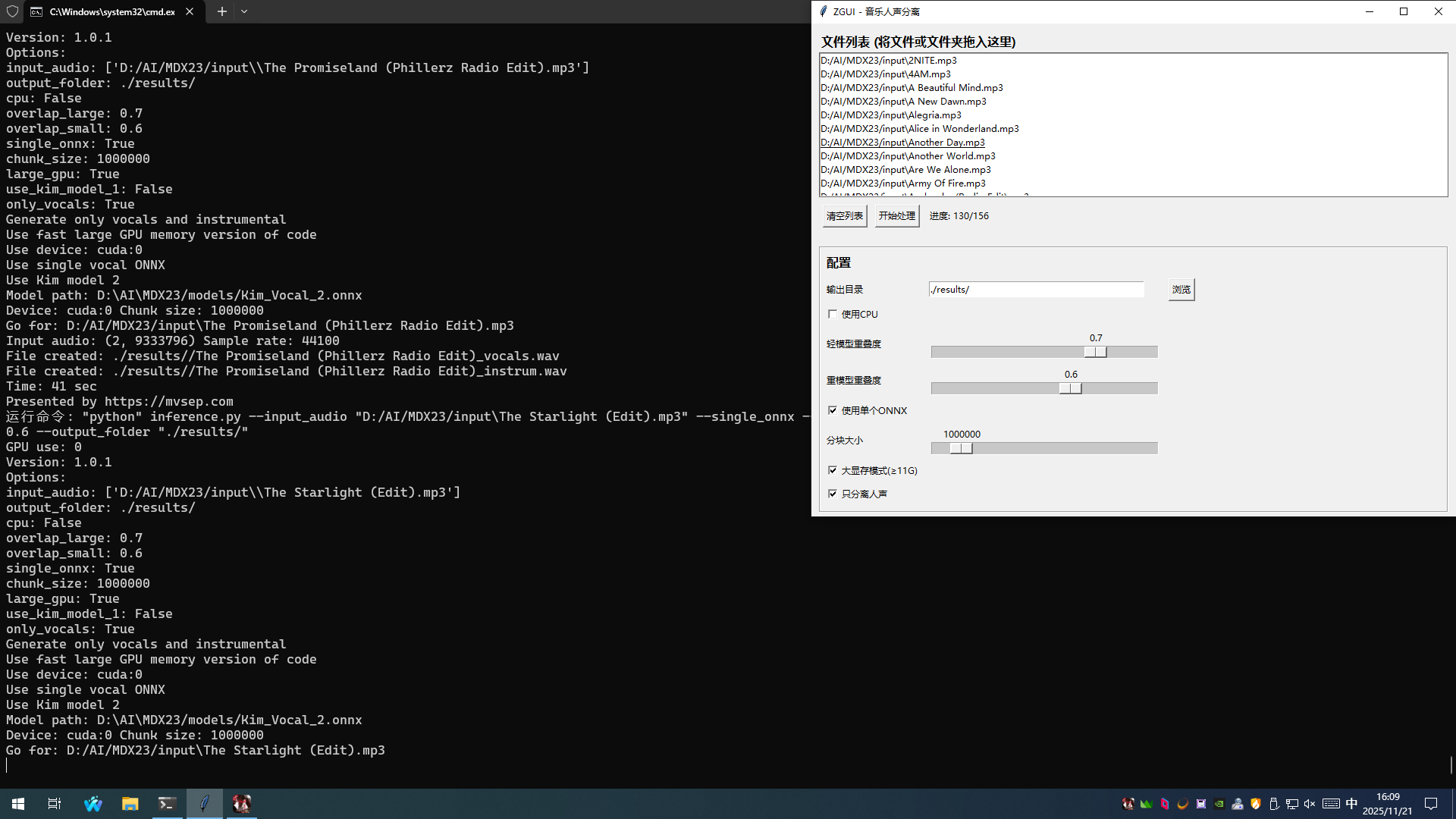
能看到处理速度还是挺不错的,用图中的配置平均35-45秒一首歌(约5-6x),2小时能处理完一个小歌单。
主要的roadblock和经验
折腾过程中自然是遇到了各种奇奇怪怪的问题,把还能记清楚的记下来吧。
网络问题
国内访问国际互联网的情况懂得都懂,所以必须是代理上场。
pip安装各种包可以直接配置清华的镜像源,虽然不是特别全(有些库会旧好几个大版本或者没收录),但速度确实是顶尖快,深圳电信测试情况是能跑到40-80 MB/s,而华为、腾讯的镜像有的限速有的就是慢。
但在实际使用python程序时,代理就是不可或缺的了。如果配置系统代理,那么多数网络库都会遵循系统代理设置,但总会遇到有些不走代理的(印象中conda就是从来不管系统代理,每次都卡在下载git或者torch上,非常蛋疼)。
解决方法:设置环境变量,HTTP_PROXY和HTTPS_PROXY都设为代理服务器地址,如http://127.0.0.1:10809。
设置完了之后还遇到过一次奇葩问题,koboldCpp没法连接到自己的API端点,一看发现localhost全走代理去了,代理软件里设置localhost直连也不行;最后继续设置了NO_PROXY环境变量才解决的(如localhost,127.0.0.1,::1)
pytorch老大难
众所周知,50系显卡用的新架构(指价格提升更大但性能提升更小了),导致torch直接不兼容;尝试在50显卡上跑老torch时会提示兼容性问题,因为新卡支持的计算能力是sm120,而旧版本只能兼容sm70、sm80等老卡的计算能力。
遇到这种问题没啥好办法,只能是在对应的环境下更新torch到新版(通常就是2.9.1这种最新版);目前按我部署过的应用来看直接更新通常不会导致什么问题,这一点比天天换API的tensorflow强多了。
(Seriously,我当时装tf的时候两个版本之间连获取版本的入口都能变,就tf.__version__都是有的版本能跑有的不能,貌似是v2能用但v3给砍了,就离谱)
但麻烦还不止在这,安装demucs之后能开始处理,但保存文件就会报错(无法加载codec相关dll);检查发现新版的torchaudio在__init__.py里使用了torchcodec库,但这个库可以说就没做Windows+CUDA的支持,官方提供的conda安装方案最后也是报奇怪的gbk错误无法安装,CPU版本又不能和CUDA版torch配合使用。而2.7.1的老版torchaudio就根本不存在调用torchcodec的行为,运行非常顺利。(没仔细调查,也可能是demucs库的问题,但反正有MDX23我也懒得管了)
在实际部署的时候能用虚拟环境尽量用,实在装不上新版torch的基本只能放弃,除非只打算用CPU。
AI horde
之前折腾酒馆的时候入的坑,horde是一个分布式AI志愿计算平台,类似BOINC但更像P2P的模式。这个问题其实更多,但最后都是重新从官方仓库里装一遍就能用了。
结语
暂时只能回想起来这些了,一整个星期实际上也没折腾太多,周末估计是拿这台电脑当云主机打游戏了。
(串流又是一个大坑,moonlight、steam link/play、parsec各有各的问题,但这些就是下次再说了: )